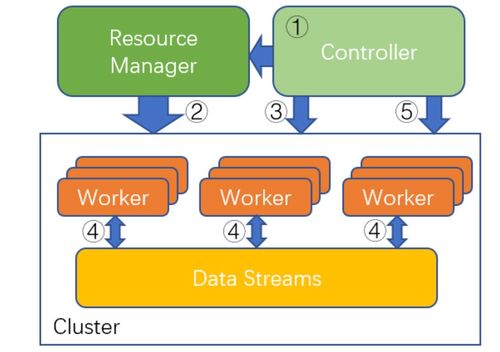
近年来,分布式强化学习(Distributed Reinforcement Learning, DRL)算法在工程和技术研究与试验发展领域取得了显著进展。这些进展不仅推动了人工智能技术的边界,还在实际应用中实现了性能的显著提升和成本的显著降低。本文将从算法优化、工程实践以及未来展望三个方面,详细探讨分布式强化学习的最新研究进展。
一、算法优化:提升学习效率与稳定性
分布式强化学习的核心优势在于其能够并行处理多个学习任务,从而加速模型的训练过程。最新的研究集中在改进算法的通信效率、数据利用率和策略协同性上。例如,通过引入异步更新机制和分层强化学习架构,研究人员成功减少了节点间的通信开销,同时提高了全局策略的收敛速度。融合元学习(Meta-Learning)和迁移学习(Transfer Learning)技术的DRL算法,能够快速适应新环境,大幅降低了重复训练的成本。这些优化不仅提升了算法的性能(如更高的奖励累积和更快的决策速度),还使得系统在复杂任务中表现更加稳定。
二、工程实践:降低成本与增强可扩展性
在工程和技术研究与试验发展方面,分布式强化学习的应用正从理论走向实践。通过采用云计算和边缘计算平台,研究人员能够灵活部署分布式训练系统,从而降低硬件和维护成本。例如,利用容器化技术(如Docker和Kubernetes)实现资源的动态分配,避免了传统集中式训练中常见的资源浪费问题。同时,开源框架(如Ray和Acme)的成熟,使得开发者能够快速构建和测试DRL模型,进一步压缩了研发周期和成本。在实际场景中,如自动驾驶、机器人控制和智能游戏系统,这些工程优化已证明能够将训练时间缩短50%以上,并减少30%的硬件投入。
三、未来展望:推动智能系统普及
尽管分布式强化学习已取得长足进步,但未来仍面临挑战,如数据隐私、算法公平性和能源消耗等问题。研究人员正致力于开发更高效的分布式架构,例如结合联邦学习(Federated Learning)以保护用户数据,同时探索轻量级模型以减少计算资源需求。这些努力将进一步推动DRL在医疗、工业和消费电子等领域的广泛应用,实现性能与成本的双重优化。
分布式强化学习算法的最新进展标志着人工智能技术向更高效、更经济的方向迈进。通过持续的工程创新和算法优化,我们有理由相信,分布式强化学习将在未来成为智能系统发展的核心驱动力,为社会带来更多便利与价值。